5
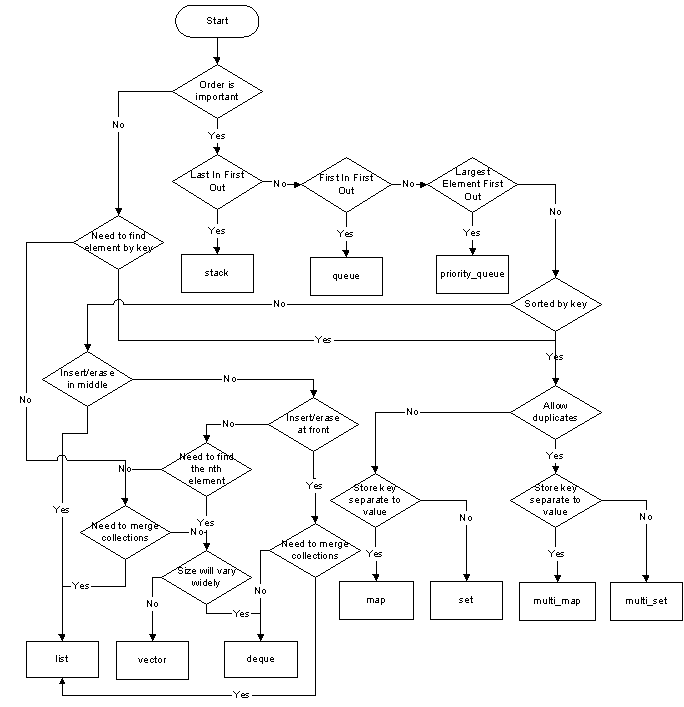
Voglio memorizzare le stringhe e rilasciare ciascuna un numero ID univoco (un indice andrebbe bene). Avrei solo bisogno di una copia di ogni stringa e ho bisogno di una rapida ricerca. Controllo se la stringa esiste nella tabella abbastanza spesso da notare un impatto sulle prestazioni. Qual è il miglior contenitore da usare per questo e come posso cercare se la stringa esiste?per la ricerca rapida dei nomi
{kind=link}
Non utilizzare unordered_map in T1, non ha il metodo di riserva e se si inserisce un sacco di corda durante la fase di inserimento che si sta per avere un sacco di rimaneggiamento. –
Anche unordered_map per stringhe lunghe è peggiore di un std :: map –