5
Mi chiedo cosa succede quando ci sono più colonne non PK in una tabella. Ho letto questo esempio: http://johnsanda.blogspot.co.uk/2012/10/why-i-am-ready-to-move-to-cql-for.htmlPiù colonne nelle tabelle Cassandra
che dimostra che con la sola colonna:
CREATE TABLE raw_metrics (
schedule_id int,
time timestamp,
value double,
PRIMARY KEY (schedule_id, time)
);
Otteniamo:
ora mi chiedo cosa succede quando abbiamo due colonne:
CREATE TABLE raw_metrics (
schedule_id int,
time timestamp,
value1 double,
value2 int,
PRIMARY KEY (schedule_id, time)
);
stiamo andando a finire con qualcosa di simile:
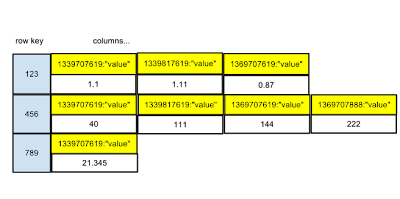
row key columns...
123 1339707619:"value1" | 1339707679:"value2" | 1339707784:"value2"
...
o meglio:
row key columns...
123 1339707619:"value1":"value2" | 1339707679:"value1":"value2" | 1339707784:"value1""value2"
...
ecc Credo che quello che sto chiedendo è se questo sta per essere una tabella sparsa visto che Inserisco solo "valore1" o "valore2" alla volta.
In tali situazioni, se voglio memorizzare più colonne (una per ogni tipo, ad esempio doppio, int, data, ecc.), Sarebbe meglio forse disporre di tabelle separate anziché memorizzare tutto in un'unica tabella?