Tipicamente, un programma per computer utilizza quattro tipi di aree di memoria (chiamati anche sezioni o segmenti):
- La sezione
text: contiene il codice di programma. È riservato quando il programma viene caricato dal sistema operativo. Quest'area è fissa e non cambia mentre il programma è in esecuzione. Sarebbe meglio chiamare la sezione "codice", ma il nome ha ragioni storiche.
- La sezione
data: contiene variabili del programma. È riservato quando il programma viene caricato e inizializzato su valori definiti dal programmatore. Questi valori possono essere modificati dal programma mentre viene eseguito.
- stack: area di memoria dinamica. Viene utilizzato per memorizzare i dati per le chiamate di funzione. Funziona fondamentalmente "spingendo" i valori sullo stack e scoppiando dallo stack. Questo è anche chiamato "LIFO": ultimo nella prima uscita. È qui che risiedono le variabili locali di una funzione. Se una funzione viene completata, i dati vengono rimossi dallo stack e vengono persi (in pratica).
- heap: questa è anche una regione di memoria dinamica. Ci sono funzioni speciali nel linguaggio di programmazione che "allocano" (riserva) un pezzo di quest'area su richiesta del programma. Un'altra funzione è disponibile per restituire quest'area all'heap se non è più richiesta. Poiché i dati vengono rilasciati in modo esplicito, possono essere utilizzati per memorizzare dati che vivono più a lungo di una semplice chiamata di funzione (diversa dalla pila).
i dati relativi text e data sezione vengono memorizzati nel file di programma (che si possono trovare in Linux per esempio usando objdump (aggiungere un . ai nomi). pila e mucchio non vengono memorizzati da nessuna parte nel file in cui sono allocati dinamicamente (on-demand) dal programma stesso.
Normalmente, dopo che il programma è stato caricato, l'area di memoria reamining è trattata come un blocco unico grande dove entrambi, pila e hea p si trovano. Iniziano dall'estremità opposta di quell'area e crescono l'una verso l'altra. Per la maggior parte delle architetture, l'heap cresce da indirizzi di memoria bassi ad alti (in ordine crescente) e stack in ordine decrescente (decrescente). Se si intersecano, il programma ha esaurito la memoria. Poiché ciò potrebbe accadere inosservato, lo stack potrebbe corrompere (cambiare i dati estranei) l'heap o viceversa. Ciò può comportare qualsiasi tipo di errore, a seconda di come/quali dati sono stati modificati. Se lo stack viene corrotto, questo può portare al lancio del programma (questo è in effetti un modo in cui un trojan potrebbe funzionare). I moderni sistemi operativi, tuttavia, dovrebbero adottare misure per rilevare questa situazione prima che diventi critica.
Questo non è solo per x86, ma anche per la maggior parte delle altre famiglie di CPU e sistema operativo, in particolare: ARM, x86, MIPS, MSP430 (microcontrollore), AVR (microcontrollore), Linux, Windows, OS-X, iOS, Android (che utilizza il SO Linux), DOS. Per i microcontrollori, spesso non c'è heap (tutta la memoria viene allocata in fase di esecuzione) e lo stack può essere organizzato in modo leggermente diverso; questo vale anche per i microcontrollori Cortex-M basati su ARM. Ma comunque, questo è un argomento abbastanza speciale.
responsabilità: questo è molto semplificata, quindi per favore commenti del tipo "come su BSS, const, myspecialarea" ;-). Non esiste inoltre alcun requisito dallo standard C per queste aree, in particolare per utilizzare un heap o una pila. Effettivamente ci sono implementazioni che non usano neanche. Si tratta della maggior parte dei casi di sistemi embedded con MCU o DSP di piccole dimensioni (8 o 16 bit). Anche le architetture moderne utilizzano i registri CPU invece dello stack per passare i parametri e mantenere le variabili locali. Quelli sono definiti nell'interfaccia binaria di applicazione della piattaforma di destinazione.
Per lo stack, è possibile leggere il wikipedia article. Notare la differenza di implementazione tra lo "stack" della struttura dati e lo "stack hardware" come implementato in un tipico (micro) processore.
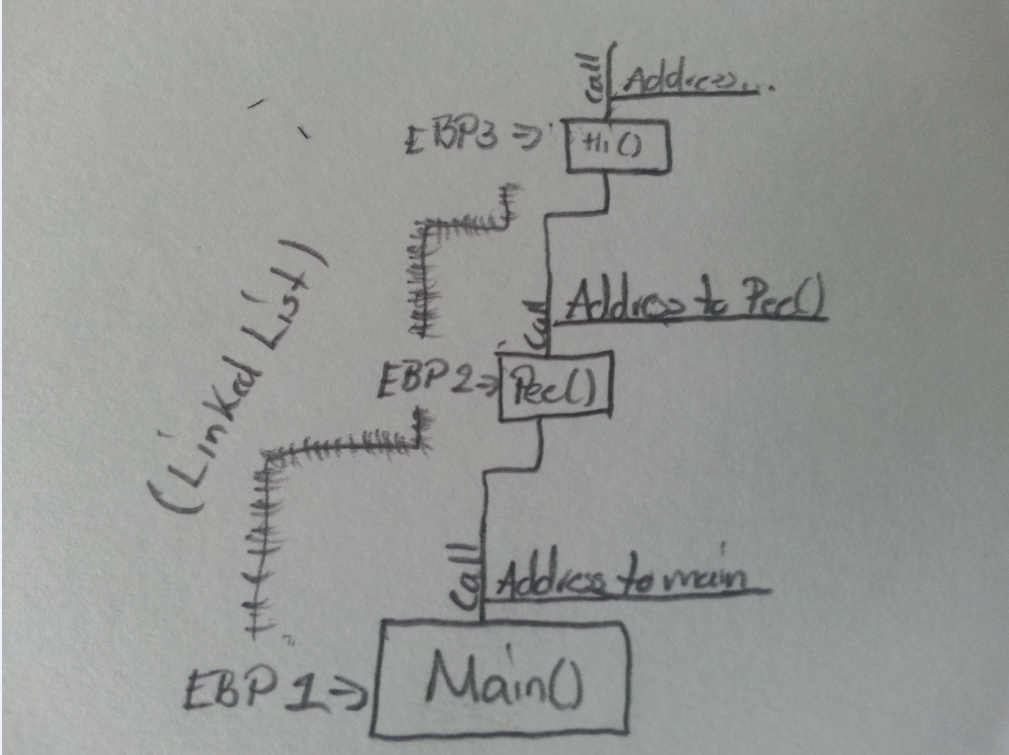
Stai chiedendo informazioni sullo stack ma nel diagramma sembra chiamarlo 'ebp'. Se fosse intenzionale, penso di sapere cosa ti ha confuso. – usr2564301
Vai alla tua mensa della scuola e guarda il congegno che contiene i piatti; la cosa elastica che si apre su un altro piatto quando prendi il primo. * Quella * è una pila. Non ho idea di chi abbia piantato la bottiglia di coca in testa. – WhozCraig
@Jongware Sì, era intenzionale. Pensavo che l'EBP fosse solo un qualche tipo di indicatore di quale fotogramma è il fotogramma corrente, motivo per cui ho scritto EBP 1, EBP 2, ecc. Quando si effettua una chiamata, non è la funzione chiamata, la nuova EBP? –