Non sono del tutto sicuro che questa domanda sia appropriata per Stack Overflow, ma andrò avanti e dare comunque una risposta di base. Anche se in realtà è una domanda molto complicata perché, a seconda di quanto in profondità vuoi andare a rispondere, potrei scrivere un intero libro sull'architettura dei computer per farlo.
Quindi, per semplificare, ti darò solo questo: è tutta una questione di contesto. Per prima cosa basta affrontare il testo:
Quando si apre, diciamo, un editor di testo l'ipotesi implicita è che i dati da visualizzare in esso sono di natura testuale. Il testo da visualizzare è alcuni byte in memoria (probabilmente copiati da alcuni byte sul disco). Non c'è un contesto interno magico dal punto di vista della memoria che questi byte siano testo. Invece, l'origine per l'editor di testo contiene alcuni comandi che puntano a quei byte e dicono "questi byte rappresentano 300 caratteri di testo", per esempio. Poi c'è una complessa sequenza di passaggi che coinvolge il codice della libreria fino all'hardware che gestisce la mappatura di quei byte secondo una codifica ASCII (ci sono molti altri modi di codificare il testo) ai caratteri, trovando quei caratteri in un font, scrivendo quel font in lo schermo, ecc.
Il punto è che non è avere interpretare quei byte come testo. Lo fa perché è quello che fa un editor di testo. Potresti ipoteticamente aprirlo in un programma immagine e dirgli di interpretare quegli stessi 300 byte come un array 10x10 (o immagine) di valori RGB.
Come per i colori vale la stessa logica. Sono solo byte in memoria. Ma quando il codice che sta disegnando qualcosa sullo schermo ha deciso quali pixel vuole scrivere con quali colori, li reindirizzerà tramite una mappatura della memoria alla scheda video che poi li tradurrà in comandi inviati al monitor (ancora in alcuni formati binari che rappresentano i pixel e i colori, anche se la realtà è molto più complicata) e il monitor stesso contiene il firmware che quindi gestisce i dettagli della mappatura di quei colori ai pixel fisici. I numeri che rappresentano i colori stessi verranno ad un certo punto convertiti in una specifica corrente per ciascun canale R/G/B per aumentare o diminuire la sua intensità.
Questo è tutto quello che ho tempo per ora ma è un inizio.
Aggiornamento: Solo per illustrare il mio punto, ho preso il testo di Flatland da here. Che è solo 216624 byte di testo ASCII (interpretato come tale dal tuo browser basato sul contesto: l'estensione .txt aiuta, ma il web server fornisce anche un'intestazione di tipo MIME che informa il browser che dovrebbe essere interpretato come testo semplice. potrebbe anche analizzare i byte per determinare che il loro modello assomiglia a quello di testo semplice (e che non ci sia un numero schiacciante di byte che non rappresentano caratteri ASCII).Ho aggiunti alcuni spazi alla fine del testo in modo che la sua lunghezza è di 217.083, che è 269 * 269 * 3 e poi tracciate come una 269 x 269 immagini RGB:
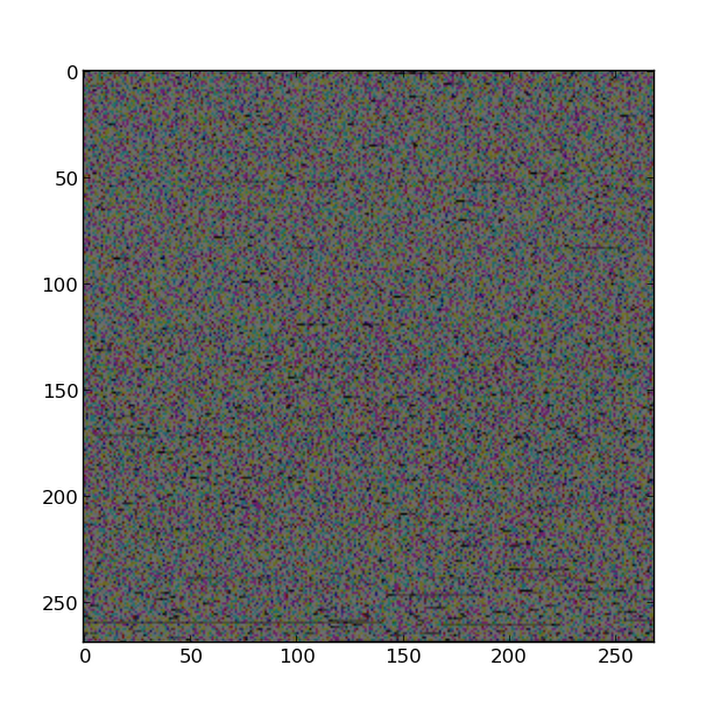
Non
terribilmente interessante dall'aspetto . Ma il punto è che ho appena preso quegli stessi byte esatti e ho detto al software, "okay, questi sono i valori RGB ora". Questo non vuol dire che guardare i byte di testo normale come immagini non può essere utile. Ad esempio, può essere un modo utile per visualizzare un algoritmo di crittografia. This mostra un'immagine che è stata crittografata con un algoritmo piuttosto insicuro - è ancora possibile ottenere un ottimo senso dei pattern di byte nel file originale non criptato. Se si trattasse di testo e non di un'immagine, ciò non sarebbe diverso, poiché il testo in una lingua specifica come l'inglese ha anche modelli statistici noti. Un buon algoritmo di crittografia sembrerebbe rendere l'immagine crittografata più simile al rumore casuale.
{kind=link}
Oltre alla mia risposta di seguito, se si desidera sapere come funzionano i computer a partire dal livello più basso, suggerisco questa lettura: Computer Organization and Design (autori Patterson, Hennessy). Se lo leggi (o leggi qualsiasi materiale equivalente), vedrai anche come funziona la CPU, e otterrai una migliore comprensione della macchina e dei suoi numerosi livelli. – Numbers
Sì, sono d'accordo. Penso che un libro sull'architettura/organizzazione comp soddisfi molte mie recenti curiosità. Buona chiamata, grazie. – ThisBetterWork
+1 al suggerimento di @Numbers. Stavo per suggerire lo stesso libro. – Iguananaut