Per uno dei miei progetti di corso ho iniziato a implementare "classificatore bayesiano di Naive" in C. Il mio progetto consiste nell'implementare un'applicazione di classificazione di documenti (in particolare spam) utilizzando enormi dati di addestramento.Problema con funzionamento in virgola mobile di precisione in C
Ora ho problemi nell'implementare l'algoritmo a causa delle limitazioni nel tipo di dati del C.
(Algoritmo sto usando è dato qui, http://en.wikipedia.org/wiki/Bayesian_spam_filtering)
problema dichiarazione: L'algoritmo consiste nel prendere ogni parola in un documento e calcolando la probabilità di esso che è parola spam. Se p1, p2 p3 .... pn sono le probabilità della parola-1, 2, 3 ... n. La probabilità di essere doc spam o non viene calcolato utilizzando

Qui, valore di probabilità può essere molto facilmente intorno 0.01. Quindi, anche se uso il tipo di dati "double", il mio calcolo andrà a finire. Per confermare questo ho scritto un codice di esempio indicato di seguito.
#define PROBABILITY_OF_UNLIKELY_SPAM_WORD (0.01)
#define PROBABILITY_OF_MOSTLY_SPAM_WORD (0.99)
int main()
{
int index;
long double numerator = 1.0;
long double denom1 = 1.0, denom2 = 1.0;
long double doc_spam_prob;
/* Simulating FEW unlikely spam words */
for(index = 0; index < 162; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom1 = denom1*(long double)(1 - PROBABILITY_OF_UNLIKELY_SPAM_WORD);
}
/* Simulating lot of mostly definite spam words */
for (index = 0; index < 1000; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom1 = denom1*(long double)(1- PROBABILITY_OF_MOSTLY_SPAM_WORD);
}
doc_spam_prob= (numerator/(denom1+denom2));
return 0;
}
ho provato float, double e anche lunghi tipi di dati double, ma ancora lo stesso problema.
Quindi, diciamo in un documento di 100K parole che sto analizzando, se solo 162 parole hanno l'1% di probabilità di spam e 99838 rimanenti sono vistosamente parole di spam, quindi la mia app lo dirà come Not Spam doc a causa di errore di precisione (come numeratore facilmente va a ZERO) !!!.
Questa è la prima volta che sto riscontrando questo problema. Quindi, come esattamente dovrebbe essere affrontato questo problema?

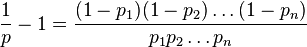



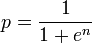
+1. Ho aggiornato la mia risposta. Penso che la cosa migliore sia combinare entrambi gli algoritmi, dal momento che la mia subisce meno perdite di precisione per il calcolo dei fattori, e la tua meno per il calcolo del prodotto complessivo. – back2dos